
Grounded-SAM:赋予机器智慧之眼,检测即分割,文字重塑AI描绘,驾驭万千图像分割可能 - 精选真开源,释放新价值。

概览
在数字化时代,图像处理技术的进步为我们打开了新世界的大门。GitHub上的开源项目"Grounded-Segment-Anything"正是这一进步的杰出代表。该项目致力于将先进的计算机视觉和自然语言处理技术结合起来,实现前所未有的图像语义分割能力。它的核心特色在于其创新性地结合了Grounding项目 DINO 和 Segment Anything 两种技术框架,从而让模型可以根据文本指令精准地定位并分割图像中的特定对象或区域,实现了对具有图像、文本和语音输入的内容进行自动检测、分割和生成,无论是常见物体还是罕见场景,都能轻松应对。
Grounded-Segment-Anything 项目以其强大的功能和灵活的应用性,为 AI 图像处理领域带来了新的突破。它不仅推动了零样本学习技术的发展,也为图像检测、分割和生成任务提供了一个统一且高效的解决方案。随着社区的不断壮大和项目的持续完善,Grounded-Segment-Anything 有望成为AI计算机视觉领域的一个里程碑项目。


截至发稿概况如下:
软件地址:https://github.com/IDEA-Research/Grounded-Segment-Anything
软件协议:Apache-2.0
编程语言:
收藏数量:13K
主要功能
由IDEA-CVR主导的Grounded-SAM项目,可以通过任意组合Foundation Models,实现各种视觉工作流场景的应用。 发布的Grounded-SAM v0.1版本中最酷炫的功能是:可以实现只输入图片,就可以无交互式完全自动化标注出图片的检测框和分割掩码。
在线体验地址:https://modelscope.cn/studios/tuofeilunhifi/Grounded-Segment-Anything/summary
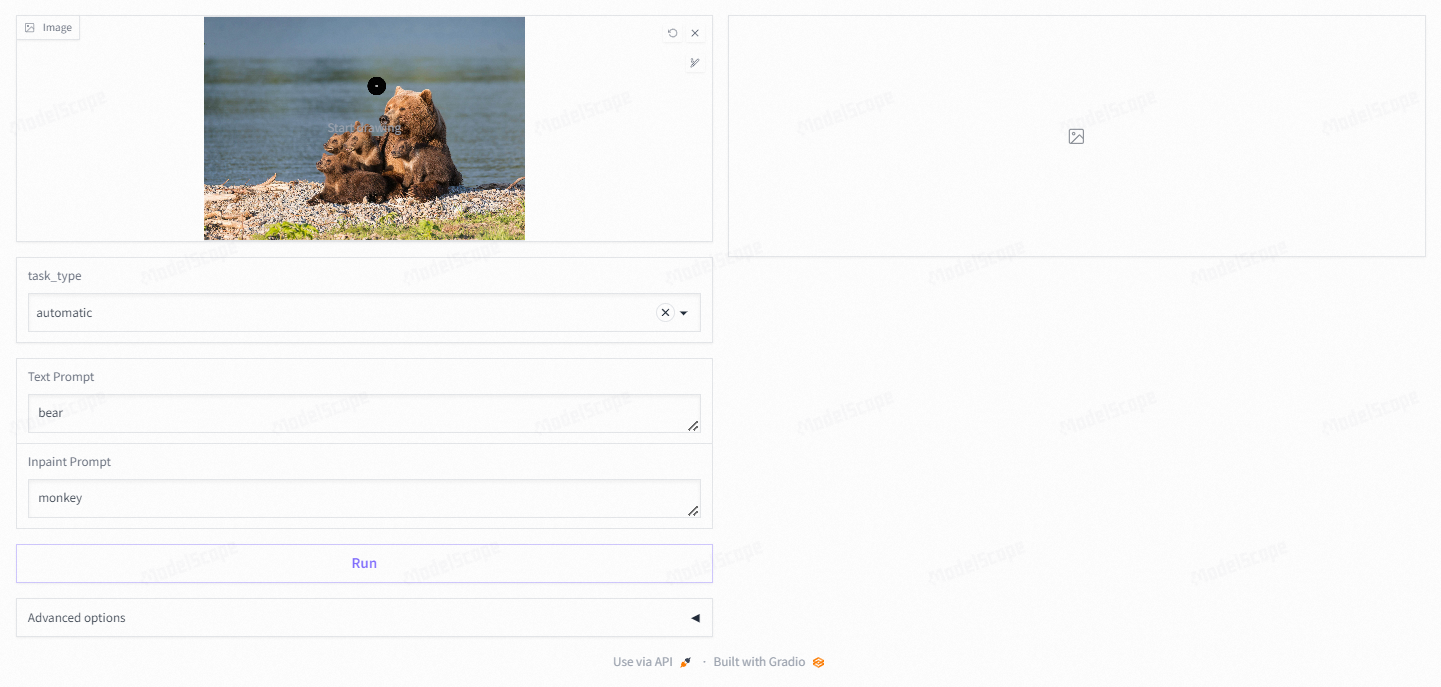
图像自动检测与分割
Grounded-Segment-Anything 能够通过文本提示自动检测图像中的物体,并生成精确的分割掩码。它展示了出色的泛化性能,能够在各种复杂的场景下对几乎任何可见物体进行有效分割,无论是常见的日常物品还是特殊的专业领域对象,只要通过合适的文本描述,都能得到准确的结果。用户只需提供简单的文本描述,如“一只猫”,系统就能识别并分割出图像中对应的物体。
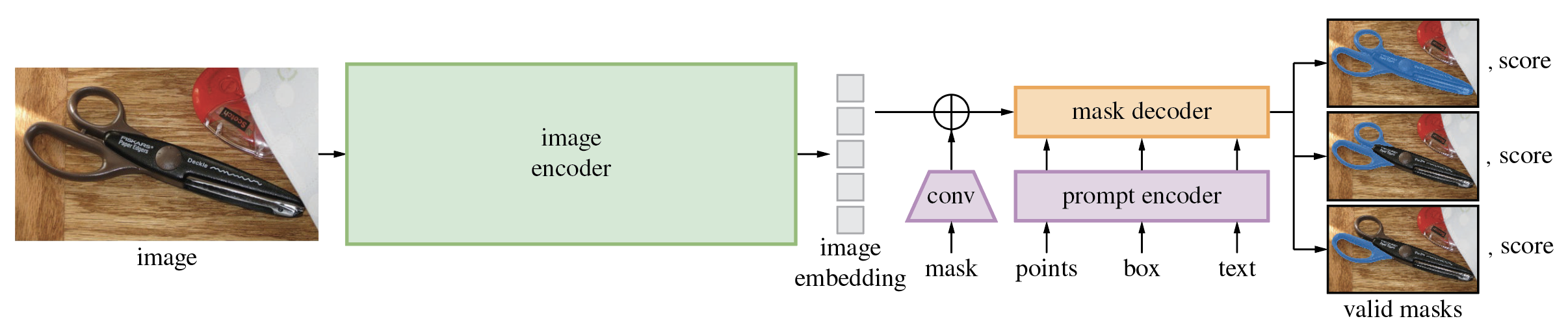

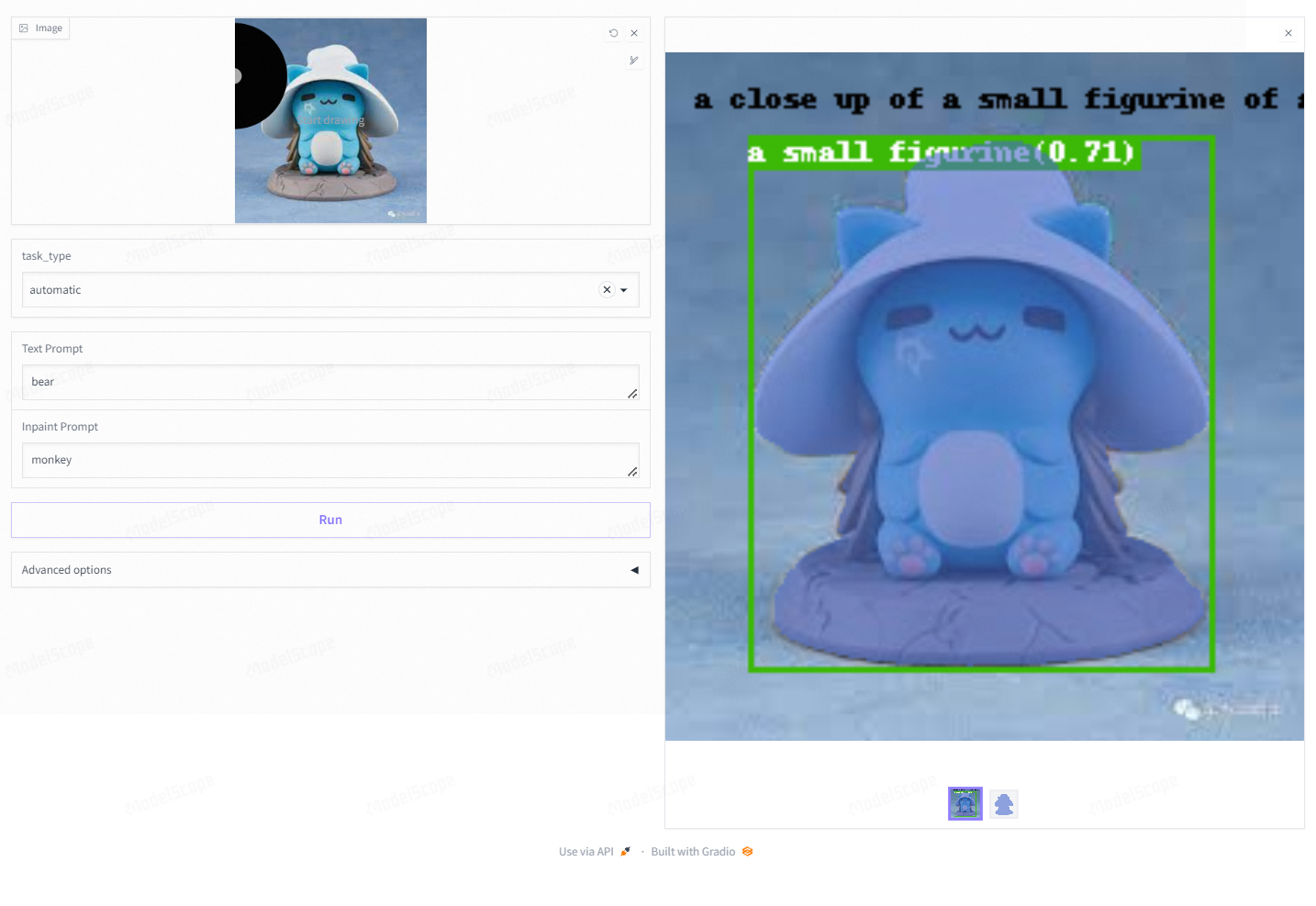
多模态输入处理
Grounded-Segment-Anything 强调跨模态交互,允许用户通过自然语言输入指导模型进行分割任务,支持图像、文本和语音输入,打破了传统分割方法仅依赖于图像特征本身的局限,增强了模型的理解和推理能力,提高了使用的灵活性和便捷性。
零样本迁移学习
Grounded-Segment-Anything 利用零样本迁移学习技术,无需针对特定领域额外训练数据,即可在新的图像领域中执行任务。并且提供详细的环境配置教程和云服务器部署指南,方便开发者快速上手并在不同的计算资源环境下运行项目,包括但不限于本地GPU、云服务器(如腾讯云CVM)等。
图像编辑与生成
结合稳定扩散模型,项目不仅可以分割图像,还能对分割后的区域进行图像编辑和生成,创造出新的视觉效果。


自动化标注系统
通过集成 BLIP 模型,Grounded-Segment-Anything 能够自动为图像生成标题和标签,并提供精确的框标注和掩码标注。

遐想
Grounded-Segment-Anything作为一项创新的计算机视觉技术,正在开拓图像处理领域的新边疆。通过其高度灵活的分割能力,它能够识别并精准分割图像中的任何物体,为研究人员和开发者提供了一个强大的工具,以应对从自动驾驶、机器人视觉到医疗影像分析等多样化的应用场景。在未来的世界里,Grounded-Segment-Anything 或许将成为智能视觉系统的重要基石,这一项目的研究,也许就是未来真正意义上的AI视觉的前置条件。
即便如今的Grounded-Segment-Anything如此优秀,但是,仍然存在一些挑战与潜在的改进空间:
语义理解复杂度:尽管项目在当前已取得显著进展,但面对更复杂的自然语言指令或模糊描述时,模型的语义理解和对应图像区域分割的准确性仍有待提高。
实时响应能力:随着处理数据量和复杂度的增加,如何保证模型在处理大尺寸图像或视频流时仍能保持高效的实时响应速度,是一个需要进一步攻克的技术难题。
隐私与伦理问题:随着这种技术的普及,如何确保在获取和处理个人敏感图像信息时充分尊重隐私权,避免滥用,是未来发展过程中必须认真对待的问题。
大家可以尽情体验Grounded-Segment-Anything的强大能力。对于跨模态交互的图像分割技术,你认为还有哪些潜在的应用场景和挑战?又该如何进一步优化模型的语义理解和分割精度,使之更好地服务于实际应用呢?各位是否遇到了有趣的问题或产生了深度思考?热烈欢迎各位在评论区分享交流心得与见解!!!